Building InsightFlow: LangGraph Implementation & Production Metrics
Technical Deep-Dive and Real Pilot Performance Data from two-phase development
This is Part 2 of my multi-agent AI orchestration analysis. In Part 1, I compared the strategic frameworks →. Now for the implementation reality.
After choosing LangGraph for InsightFlow's multi-agent coordination (covered in Part 1), the real work began: building a system that could orchestrate specialized AI agents into coherent learning conversations. Here's what I've learned across two pilot iterations.
Table of Contents
- Two-Phase Pilot Development
- Current Architecture
- Agent Coordination Pattern
- State Management Reality
- Evaluation Results
- Production Learnings
- Architectural Decision Guide
- What's Next
1. Two-Phase Pilot Development
Phase 1: Chainlit-Based Prototype
My initial implementation used Chainlit as the primary interface, which proved invaluable for rapid prototyping and understanding multi-agent coordination patterns.
What worked with Chainlit:
- Rapid prototyping: From concept to working multi-agent interface in days
- Real-time streaming: Agent coordination visible to users as it happened
- Built-in RAGAS integration: Could evaluate conversation quality in real-time
- Development velocity: Perfect for experimenting with agent coordination patterns
Key learnings from Phase 1:
- Multi-agent coordination needs visual feedback for both developers and users
- Real-time streaming makes the "thinking process" transparent and engaging
- RAGAS metrics provide valuable signals for tuning agent interactions
- State management becomes critical as conversations extend beyond simple exchanges
Phase 2: Production Architecture (Current)
Phase 1 taught me that streaming coordination matters, so in Phase 2 I moved the backend to Google Cloud for better async control while preserving the real-time patterns that worked.
Current Architecture:
- FastAPI Backend (Google Cloud) - Python-friendly ML stack with better async processing
- React/Next.js Frontend (Vercel) - More flexible UI for complex interactions
- PostgreSQL - Robust state persistence for extended conversations
- LangGraph Orchestration - Refined agent coordination patterns from Phase 1
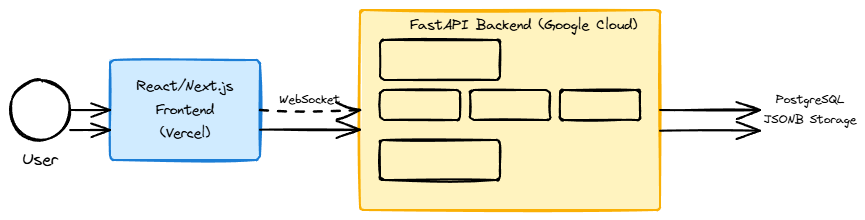
2. Current Architecture
Technical Stack:
Full Architecture Details
FastAPI Backend (Google Cloud)
├── LangGraph Orchestration Layer
│ ├── Agent Nodes: analyst_agent, creative_agent, synthesis_agent
│ ├── Shared State Management
│ └── Real-time streaming coordination
├── PostgreSQL (JSONB conversation state)
└── React/Next.js Frontend (Vercel)
Architecture decisions:
- Google Cloud for FastAPI: Python-friendly ML stack with better async control
- Vercel for React frontend: Optimized for real-time WebSocket connections
- PostgreSQL over document stores: JSONB provides flexibility with ACID guarantees
- Retained streaming patterns: Chainlit taught me that visible coordination matters
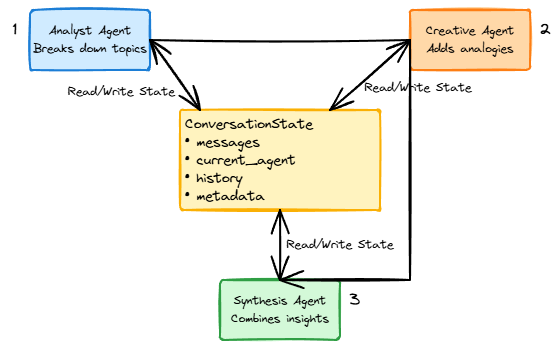
3. Agent Coordination Pattern
The core insight from both phases: treat agent coordination as a state machine where each agent contributes to shared conversation context.
Agent Roles Refined Through Testing:
- Analyst Agent - Breaks down complex topics into structured components
- Creative Agent - Provides analogies, examples, and alternative perspectives
- Synthesis Agent - Combines insights from previous agents into coherent responses
State Management:
class ConversationState(TypedDict):
messages: List[HumanMessage | AIMessage]
current_agent: str
conversation_history: Dict
coordination_metadata: Dict
Each agent accesses the full conversation state while maintaining its specialized processing logic.
4. State Management Reality
LangGraph + PostgreSQL Implementation
Checkpoint-based persistence (current design):
- Conversation state saved to PostgreSQL at natural conversation breakpoints
- JSONB storage for flexible conversation state and learning analytics
- Automatic state recovery for conversations spanning multiple sessions
- No context window limitations for extended learning sessions
State synchronization:
# Simplified state update pattern
def update_conversation_state(state: ConversationState, agent_response: str) -> ConversationState:
state["messages"].append(AIMessage(content=agent_response))
state["coordination_metadata"]["last_agent"] = agent_type
state["conversation_history"]["agent_contributions"] += 1
return state
Comparison with Assistants API
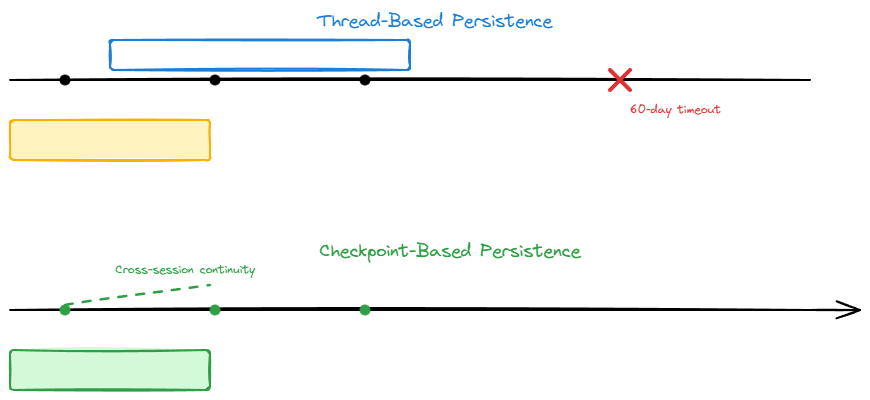
| Approach | State Management | Production Reality |
|---|---|---|
| Assistants API | Thread-based with 60-day timeout | Manual thread ID tracking, context window management up to 128k |
| LangGraph + PostgreSQL | Checkpoint-based state persistence | Automatic state recovery, unlimited conversation history |
5. Evaluation Results
Testing Approach: Evaluated 25 conversations from Phase 1 Chainlit testing across 5 learning scenarios.
Implementation:
results = evaluate(dataset, [context_precision, faithfulness, answer_relevancy])
Coordination Quality Results
Phase 1 RAGAS Scores (n=25 conversations):
- Context Precision: 0.89 (measures how well agents use relevant information rather than hallucinating—critical for learning applications where accuracy builds trust)
- Faithfulness: 0.92 (multi-agent response consistency across the conversation)
- Answer Relevancy: 0.87 (topic coherence across agent contributions)
Performance Comparison
| Phase | Average Latency | Infrastructure | Development Speed |
|---|---|---|---|
| Phase 1 (Chainlit) | ≈2.1s | Single service | Extremely fast prototyping |
| Phase 2 (FastAPI) | ≈1.8s | Multi-service | Slower setup, more control |
6. Production Learnings
Error Recovery Patterns
What I discovered: Current design handles errors by graceful degradation—the system continues with remaining agents when one fails, preserving conversation context despite agent failures, and implementing retry logic so failed agents can rejoin coordination on the next interaction.
# Example: Graceful degradation when Creative Agent fails
if creative_agent_available:
response = await orchestrate_full_pipeline(state)
else:
response = await analyst_synthesis_fallback(state)
# Log degradation for monitoring
Cost Optimization Strategies
- Conditional agent activation: Not every conversation requires all three agents (reduced per-conversation costs by ~40% compared to always-on three-agent coordination)
- Shared context efficiency: Single state object reduces redundant context passing
- Optimized checkpointing: Balance between data safety and database load
Debugging Multi-Agent Workflows
LangGraph Studio's visual debugging proved essential for:
- Flow visualization: See exactly where conversations get stuck
- State inspection: Real-time view of shared state changes
- Performance bottlenecks: Identify which agents create latency
7. Architectural Decision Guide
Based on testing both approaches, here's when each architecture makes sense:
When Chainlit-Style Architecture Works
- Rapid prototyping: Getting multi-agent concepts working in days, not weeks
- Research and experimentation: Understanding how agents should coordinate
- Educational applications: Built-in streaming and evaluation tools
- Small team development: Single developer can manage entire stack
When FastAPI + Custom Frontend Wins
- Production scalability: Need to handle multiple concurrent users
- Custom user experiences: UI requirements beyond standard chat interfaces
- Enterprise integration: APIs for connecting to existing systems
- Long-term maintenance: Full control over infrastructure and dependencies
The Hybrid Approach
Many teams might benefit from:
- Prototype Phase (Chainlit): Validate coordination patterns quickly
- Production Graduation (Custom): Scale validated patterns based on proven concepts
- Optimization Phase: Cost + performance tuning with full infrastructure control
8. What's Next
Current Status: Phase 2 FastAPI + React architecture actively running pilot evaluations with 15+ learning conversations weekly.
Next explorations: Applying cognitive load theory to agent coordination patterns—when does multi-agent thinking help vs. overwhelm learners? Exploring tighter coordination patterns based on learning science research, particularly around spaced repetition triggers.
Technical Deep-Dives Coming: As the production system stabilizes, I'll share more detailed architecture patterns and evaluation frameworks.
What I'm pondering next:
- Graceful degradation patterns - Maintaining conversation coherence when agents fail
- Conditional intelligence economics - Optimizing conversation complexity to computational cost
- Cross-session memory architectures - Systems that remember reasoning patterns, not just dialogue
If you're building similar systems, I'd love to hear your perspectives.
References
- LangGraph Multi-Agent Workflows Documentation. https://langchain-ai.github.io/langgraph/concepts/multi_agent/
- RAGAS: Automated Evaluation Framework. https://docs.ragas.io/en/stable/
- Es, S., et al. (2023). RAGAS: Automated Evaluation of Retrieval Augmented Generation. arXiv preprint arXiv:2309.15217
- Chainlit Documentation. https://docs.chainlit.io/
- Yao, S., et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv preprint arXiv:2201.11903
- Xi, Z., et al. (2023). The Rise and Potential of Large Language Model Based Agents: A Survey. arXiv preprint arXiv:2309.07864
- Wang, G., et al. (2023). Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv preprint arXiv:2305.16291
Acknowledgments
Special thanks to Laura Funderburk for encouraging me to share these technical explorations with the community.
Thanks also to the AI Maker Space team - Greg Loughnane and Chris Alexiuk - for exceptional instruction that shaped this exploration.
#AIEngineering #LangGraph #MultiAgentSystems #RAGAS #Chainlit #ProdAI
Got experience with multi-agent production systems? I'd especially love to hear about your error handling patterns and cost optimization strategies. What challenges have you solved that I'm still working on? 👇